CoreOS(現状Container Linuxですけど、キャッチーじゃないのであえて)上でプライベートのDockerコンテナを動かしていたのですが、それをAmazon ECS上へ移行した話です。
##従来の環境
従来は以下のような環境を使っていました。
- さくらクラウドでCoreOSを起動(イメージがデフォルトで用意されていて嬉しい)
- コンテナは個人的なログ用influxDB、Grafana、個人slack用hubotの3つ。
- オーケストレーションツールは使っていない(docker composeで管理、systemdで自動起動)
- それ以外に運用っぽいことも特にしてない。
プライベートかつ、とりあえずDocker触って動かしたいという理由だけで作った環境だったので、正直扱いは雑でして、たまにコンテナ落ちてて、hubotに呼びかけてから気付くみたいなこともままありました。
それが地味にストレスだったのと、せっかくDocker使うならもうちょいオーケストレーションとかちゃんとしたいってことで移行を決断しました。
##移行先の検討
CoreOSは従来であればfleetという独自のオーケストレーションツールを持っていましたが(今も正確には現役ですが)、このリンク先にもある通り、現状はk8s使えってことになってます。
なのでさくらクラウド続投してk8sで頑張るというのも手ではあったのですが、仕事ではAWS使うことが多いというのと、個人的にここ最近聴いたDockerのproduction利用の話がだいたいECSだったのとで、管理も楽そうだしECSでいいかなという感じでした。
ただ、k8sであればオンプレやら何やらといった環境を問わずに運用が可能だし、クラウドに載せたければGKEでそのノウハウ活かせるしという利点があり、長期視点で汎用性の高い技術選択、という視点だとk8sの方がいいのではと思ったりしてます。
##ECSの概念
簡単に触れておきます。
###cluster
コンテナをホストするEC2インスタンス群。
###task definition
cluster上でコンテナをどう配置するかという定義。
###task
task definitionに基いて稼働するコンテナ群。
###service
taskを永続的なプロセスとして稼働させるECSの機能。
taskは「service」として動かすことで、コンテナが落ちても勝手に上げ直してくれるようなイイ感じのやつになります。serviceの定義の中でAuto Scalingの設定したりとかもできるらしいですが、今回そこまでやってないです。要らないし。
##移行作業
ぶっちゃけ、すごく簡単でそんなにやったことはないです。
はじめはTerraformで環境作るかとか思ってたんですが、tfファイルをゼロから書くのがだるくなったので他にも手段があるんじゃないかと調べていたところ、ECS CLIというAWS提供のコマンドツールがありました。
で、これがtask definitionとしてdocker-compose.ymlがだいたいそのまま使えるんですね。。なのでdocker-compose.ymlからTerraformへ定義を書き写すような面倒はかけず、移行が出来てしまうわけです。実行したコマンドはこれだけです。
# clusterを起動
$ ecs-cli up --keypair hoge --size 1 --instance-type t2.micro --capability-iam --port 8080 3000 8086
# docker-compose.ymlからserviceを起動
$ ecs-cli compose --file docker-compose.yml service upこれだけでもう、コンテナはほぼ永続的に稼働します。便利ですね。今回は個人用なのでt2.microを1台しか上げてないですが、複数台インスタンスを上げればコンテナはイイ感じに分散してくれるみたいです。
ただ、ecs-cli upで賄えるのはあくまでEC2の範囲なので、ALBを使いたいですとか、EFSで各インスタンス間のデータを共有したいですとか、そういう要望がある場合にはマネジメントコンソールなりTerraformを使う必要があります。あくまで「とりあえずコンテナを動かす環境が何かあればいい」ぐらいの目的で使うものかなと。
まぁ自分の場合はプライベート用途で複雑な要件もなかったので、ECS CLIで十分です。構成管理という面でも、先のコマンドを書いたシェルスクリプトとdocker-compose.ymlさえあれば環境再現はすぐできるので、拍子抜けするほど楽でした。
##運用
当初の動機が「コンテナがバンバン落ちる不健全な環境を抜け出したい」でもあったので、多少なり運用も組み立てています。
###監視
自分がproduction環境でのDocker運用経験がほとんどないこともあり、正直ベストな監視の仕方がよくわかっていません。例えば最低10台以上のコンテナを動かしてガリガリ処理させたいような環境を動かしたいとして、稼働台数10台を下回ったらアラート上げたいと個人的には思うんですが、そういう運用でいいんですかね。それともオーケストレーションでコンテナ数確保されるから監視しなくてよい、のかどうなのか。
と言うのも、意外というかなんというか、Amazon CloudWatchではコンテナの稼働状態に関するメトリクスはほとんど取れません。CPUとメモリの使用率だけです。稼働台数ぐらいありそうなものなんですけどね。ECSの監視はどうしてんだろうみなさんというのは改めて調べておきたいところ。
結局のところ、自分は2方面で監視してます。
1つはCloudWatch Eventsで、serviceの稼動状態に変化が起きたことをトリガーとしてLambdaなどを発火できる機能があります。これを使ってコンテナが落ちたりしたときにはslackに通知されるようにしました(鏡音リンちゃんが教えてくれます)。ただ、先述の通り「落ちてもすぐ自動で上がる」ようにはなってるので、なんか頻繁に落ちてるなとか、落ちたまま上がらないなとかを気付くためだけの用途です。
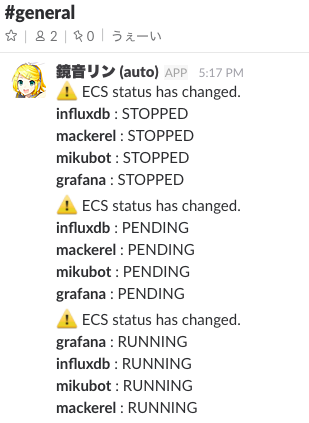
2つ目はMackerelのDockerプラグイン。
Dockerをモニタリングする - Mackerel ヘルプ
これも1インスタンス上で動いているコンテナごとのメトリクスをグラフ表示するだけなので、コンテナ個別の死活などは取れないです。あくまでメトリクスグラフの描画のために使ってます。
聴くところだとDataDogはコンテナの稼働台数とか取れるみたいですね?
###バックアップ
ECSのインスタンスを落としたらそのままデータ死ぬという状況はさすがに怖いのでバックアップ。これも悩みましたけど、ズボラにCloudWatch Eventsで日に1回EBSスナップショット取らせてます。
##罠っぽいところ
最後にハマリポイントをいくつか。
###docker-compose.ymlが必ずしも直接使えない
docker-compose.ymlがほぼそのまま使えるのは使えるのですが、具体的にはmemlimitを各コンテナで設定しておかないと、メモリ足りないと言って落ちたりします。CoreOSだとリソースなど見ずに上げろと言えば上げてくれるんですが、ECSはそのあたりシビアに見てます。
###ecs-cli service upが無限ループする
コンテナのserviceを起動するecs-cli service upコマンドですが、どうも一度起動命令を送った後、全コンテナがRUNNING状態になるのをひたすら待っているようで。
何かタスク定義に不備(先のメモリ不足とか)があるとserviceは一度落ち、そしてserviceは永続稼働前提なので再度コンテナを起動し、そしてまた落ちるという無限ループに陥るのですが、ECS CLIはそれを拾ってくれないです。なのでupしてからしばらく応答がなければ、無限ループに陥ったと判断し、コマンドキャンセルしてGUIからログとか見に行った方がいいです。
###Docker Hub Privateとの連携が面倒
ECS上でDocker Hubのプライベートレジストリに置いたイメージを動かしたい場合、cluster上のインスタンスに一旦ログインして、設定ファイルにログイン情報を書き込む必要があります。ちょっと面倒だし、手段としてもあんまりイケていない感じがするので、もう少しなんとかならないかなと。まぁECR使ってくれってことなんでしょうけど。
##まとめ
単純に「コンテナを動かす」だけであれば非常にシンプルに出来ており、docker-compose.ymlという既存の資産も使えるので、ECSが使われる理由はちょっとわかった気がします。特にECS CLIがあることで、Dockerイメージを更新したときなど、CIで自動的にデプロイをトリガーできたりするのはいいですね。
機会があればk8sも使ってみて、使い勝手とか比較したいところ。